



Observing data over time is time series. Predicting that data in the future is time series modeling. Unlike the regular prediction, this is slightly different because of the chronology in the data.
As an example say a retail outlet (call it RetaileR) observes the daily sale of goods from when the company was created. It has been five years since, and they wish to estimate the sale for the next year for two reasons:
- to assess the strength of the company and its future prospects
- to optimize its inventory stock and prevent losses due to undershooting or overshooting the estimate
Understanding this data is time series analysis. Suppose, RetaileR forecasts sales for the next six months, but due to unforeseen circumstances, the prediction for the second month goes off by 40%, there is a huge demand but the inventory is empty, and this puts the next four months into disarray. This may seem innocuous but, in certain industry sectors, inventory is stacked up to eight months in advance and so, accurate forecasts go a long way.
Usually, a manual estimate of 5% or higher around the trend corresponding to last season's sales is quite good, which any decent tool should handle quite easily. But the forecasting models are also capable of considering more complex patterns not visually obvious. In fact, it is not possible for humans to fathom when more than two variables affect the outcome. That is also one of the reasons why simple models are preferred, to understand the why behind forecasts.
Modeling techniques
Modeling techniques like ARIMA have been around for decades because they are easy to understand. Time series modeling does not need any predictor variables, the past values of the outcome variable themselves act as predictor variables. Usually, each time series needs a tailored set of parameters to fit the ARIMA model. With improvements in R packages, they have become even simpler. A simple auto.arima() will fit the series with near-optimal parameters.
There are a couple of ways to evaluate model performance. One way is to evaluate the AIC parameter for different models on the same training data, and the other is to compare the out-of-sample prediction accuracy. The caveat with AIC and AICc is that they can only be compared within the same class of models, i.e., ETS or ARIMA, etc., comparing them across different models will lead to erroneous conclusions.
The framework of making forecasts is provided by R, the challenge is to evaluate the best model for different combinations of input (from the store, category, sub-category). Each combination needs 5 different models, over different lag periods (1-12). For example, for a single Store + Category, 5 x 12 subsets are trained. So, for a chain having 5 stores, 20 categories (or 25 sub-categories) a maximum of (5 x 20(or 25) x 5 x 12 = 6000) models need to be trained (the combination of category and sub-category is ignored). Thus manual fine-tuning is not quite practical.
Forecasting approaches
There are many approaches to forecasting. I include ARIMA, TBATS, Thetam, STL, and ETS and an ensemble of these models weighted by the performance on out-of-sample accuracy. Getting back to RetaileR, firstly an aggregate of the dataset at the monthly level for each combination (category/sub-category + chain + store) is made (this creates a list of aggregated tables in R).
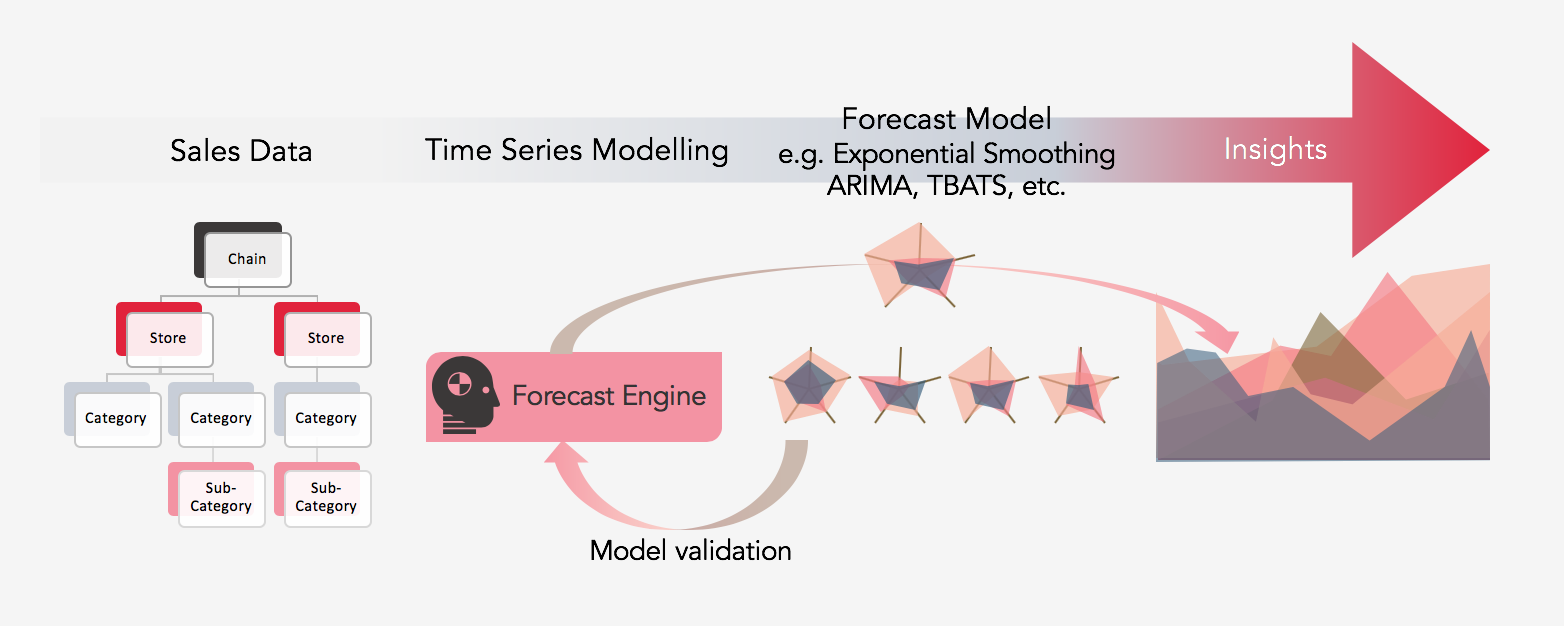
Then, the models are run on each of the individual aggregated tables (say the aggregated sale of Vegetables in-store RetaileR-Helsinki, aggregated sale of medicines in Store RetaileR-Helsinki, and so on). Each table has about 12 times 4 (years), i.e., 48 data points, which is quite tiny. An R function takes this time series as input and outputs a trained model and its test accuracy for different lags. This function is then repeatedly called for all the aggregated tables. Finally, for every category/sub-category, the 1-12 month lag forecast accuracy is averaged and compiled into an excel report. If the user so desires, just the forecast and 90% or so confidence can be got. Or, he is free to choose among the best performing models or simply a single model for all aggregated tables. There can be more customizations, like getting the forecasts for the top 10 categories, or for the categories which contribute about 90% of the sales, and so on. Imagination is the limit.
Let's supposed RetaileR has a propriety software that has been forecasting their numbers. It is quite easy to compare the forecasts obtained through R and compare it against the tools’. This can then be automatically exported as an excel file for an in-depth understanding of the comparison. On a final note, even though R comes with a lot of algorithmic punch, other tools may be superior in terms of presenting those findings. But R is still the easiest, cheapest and the best bet to test feasibility quickly.
Sales and Demand Forecasting with time series modeling
Are you working in procurement or sales? Would you like to get an automated solution that indicates what your sales will be next month or two years from now?
Our forecasting platform uses machine learning to deliver highly accurate predictions of your sales and demand. The forecasting platform:
- 1. Reduces forecasting time from days to moments
- 2. Improves forecasting accuracy
- 3. Lets you take the full benefit of your own data.


